问题是这样的
环境:Centos,Flask,Let’s Encrypt.
使用下面的方式,来安装SSL,发现在Wordpress程序上没有任何问题,而在安装Flask程序时,则出现了问题。具体往下看。
在Flask程序上申请SSL证书,出现下面的提示:
Failed authorization procedure.
The following errors were reported by the server
内容来自:https://www.freehao123.com/lets-encrypt/ 问题已经解决了,用的是Certbot,我把我的方法贴一下: 首先要说明一下几点: 1.存在一个已经建立的虚拟主机 2.我用的是oneinstack 3.Python的版本是2.7以下(如果是2.7以上SSL证书会自动安装,不用手动的) 4.使用Certbot脚本 ————-分界线————————————– 过程: 1.去Certbot的官网找到与web环境相应的脚本(官网qi姐已经贴出来了) 2.按照官网的步骤来:(这是CentOS6 ,Nginx的脚本,不要直接复制哦,要按照自己的情况来) # wget https://dl.eff.org/certbot-auto # chmod a+x certbot-auto $ ./certbot-auto ——————-分界线———————– 然后Python版本低于2.7的服务器就会出现问题了 Certbot会报错,代码如下: Installing Python packages… Installation succeeded. /root/.local/share/letsencrypt/lib/python2.6/site-packages/cryptography/__init__.py:26: DeprecationWarning: Python 2.6 is no longer supported by the Python core team, please upgrade your Python. A future version of cryptography will drop support for Python 2.6 DeprecationWarning Saving debug log to /var/log/letsencrypt/letsencrypt.log Failed to find apachectl in PATH: /usr/local/nginx/sbin:/usr/local/php/bin:/usr/local/mysql/bin:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/root/bin /root/.local/share/letsencrypt/lib/python2.6/site-packages/certbot/main.py:568: DeprecationWarning: BaseException.message has been deprecated as of Python 2.6 return e.message Certbot doesn’t know how to automatically configure the web server on this system. However, it can still get a certificate for you. Please run “certbot-auto certonly” to do so. You’ll need to manually configure your web server to use the resulting certificate. ——————-分界线————————– 我们不用管它,因为他说了,你可以手动安装SSL,那我们就手动安装 ——————-分界线—————————— 输入命令: # ./certbot-auto certonly 然后它依旧会报错,那我们依旧不管他 继续进行命令,因为我们是手动配置 ——————–分界线——————————– 再输入上面的命令以后,会出现选项,一个是独立服务器,一个是web服务 我们选择1,web服务 它会要求我们输入email(可以不输入),那我们输入email ———————–分界线—————————– 接下来它会要求我们输入域名 输入域名 ————————分界线————————— 然后它会要求我们给出域名所在的根目录 用的oneinstack的话就输入 /data/wwwroot/你的域名 ————————-分界线———————– 返回如下代码,获得SSL 证书: IMPORTANT NOTES: – Congratulations! Your certificate and chain have been saved at /etc/letsencrypt/live/ex.acgbuster.com/fullchain.pem. Your cert will expire on 2017-05-02. To obtain a new or tweaked version of this certificate in the future, simply run certbot-auto again. To non-interactively renew *all* of your certificates, run “certbot-auto renew” – If you like Certbot, please consider supporting our work by: Donating to ISRG / Let’s Encrypt: https://letsencrypt.org/donate Donating to EFF: ————————–分界线——————————-
众所周知,Flask的目录结构是:
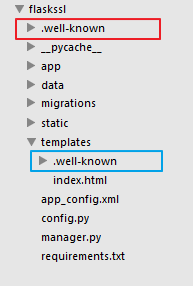
在使用
./certbot-auto certonly
命令之后,如果输入的是/flaskxxx这个目录,那么就会生成红色框内的目录(Let’s Encrypt会在网站根目录生成一个目录里面会放一个验证程序[类似于验证文件],随后程序会进行访问相关地址进行匹配),用过Flask的都知道,这个红色的目录肯定是不对的(Flask一般读取templates目录下面的文件)。
所以,在Flask上申请SSL的时候,就遇到了这个问题。
我们只能从侧面去解决这个问题。

解决方案
在你的Flask文件中加入下面的代码,然后再次执行
./certbot-auto certonly
就可以实现验证,也就可以申请到SSL证书了。
2017.5.15更新:当文件不存在时,不显示详细路径(加入try/except处理).
from flask import make_response
import os
@app.route('/.well-known/acme-challenge/<checkinfo>')
def checkSSL(checkinfo):
base_dir = os.path.dirname(__file__)
checkinfo = 'templates/.well-known/acme-challenge/'+checkinfo
try:
resp = make_response(open(os.path.join(base_dir,checkinfo)).read())
return resp
except IOError as err:
return 'File Error'
return 'hi'修改Python文件之后,如果使用的是uwsgi+nginx架构,只需要重启uwsgi即可.
ps -ef | grep uwsgi root 9977 1 0 19:41 ? 00:00:00 uwsgi -x xxx.xml -d uwsgi.log --pidfile /tmp/uwsgi.pid kill -9 9977 # 9977 是程序的进程号. # 在下面再次运行uwsgi即可.
折腾一下午这个问题……
另外,下午将目前的几个站全都升级了SSL。只是遗憾的是,国内的淘宝联盟不支持SSL,代码只能显示空白了。(百度统计,CNZZ都支持SSL,而51LA目前还不支持SSL),还好GG支持SSL,直接就可以用了。


